Evidence Retrieval Systems
Your AI can surface an answer.
That is not the same as the right one.
A wrong answer in a clinical workflow is not a UX problem. It is a trust problem that compounds — with clinicians, with enterprise buyers, and with compliance reviewers. Vantage builds the retrieval infrastructure that gives your AI product something most don't have: answers it can stand behind.

The Problem
Generic retrieval breaks in healthcare
Standard vector search was designed to find relevant text. Healthcare AI needs something different: evidence that is ranked by quality, constrained by domain, and synthesized with source accountability.
Weak source ranking
All retrieved documents compete equally regardless of evidence quality. A patient forum post and a Cochrane review carry the same weight. That is not a retrieval strategy. It is a liability.
Irrelevant retrieval
Semantic similarity is not the same as clinical relevance. A query about metformin dosing should not surface tangentially related metabolic content. Vector search alone cannot make that distinction.
No synthesis control
When retrieval fails, the language model fills in the gaps with plausible-sounding content that has no source. In healthcare, that is not a hallucination. It is a patient safety problem.
Our Approach
A system designed for the evidence, not the query
Most teams start with a vector database and ask how to make retrieval better. Vantage starts with the knowledge source and asks what the system needs to know before it retrieves anything.
The difference shows up in what your product can claim. Not just "AI-powered search" but: answers ranked by evidence quality, constrained to the right sources, and explainable to a clinician or compliance reviewer who needs to understand why. That is a different product. It earns a different level of trust.
Every answer in the system traces back to a source, a retrieval decision, and a ranking rationale. That is not a feature added at the end. It is a design constraint applied at the start.
The result is a retrieval pipeline that holds up under clinical review, enterprise security evaluation, and the scrutiny of teams whose adoption determines whether your product actually ships.
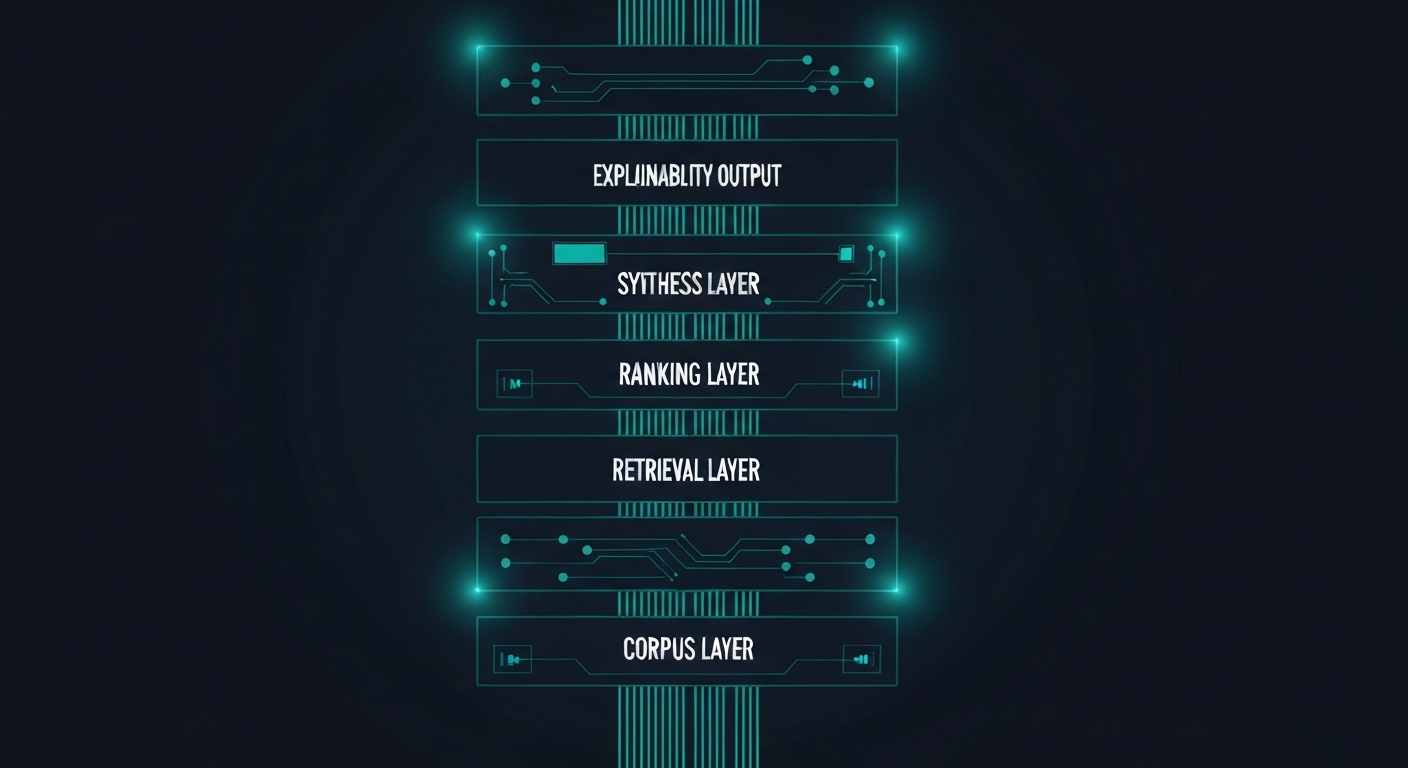
What Gets Built
Five layers that separate reliable retrieval from lucky retrieval
Each layer addresses a specific failure mode. Together they form a retrieval pipeline that is defensible end-to-end.
Corpus Curation
Source selection, normalization, and enrichment before a single query runs. What you retrieve from matters as much as how you retrieve it.
Hybrid Retrieval
Keyword search and semantic search together, not as alternatives. Each mode catches what the other misses in clinical and regulatory text.
Evidence Ranking
Deterministic scoring by source type, recency, and authority. A systematic review should not compete equally with a blog post.
Bounded Synthesis
AI-generated answers constrained to what was retrieved. The model summarizes; it does not speculate beyond the retrieved set.
Explainability Layer
Every answer traceable to its source and reasoning path. A clinician or auditor can follow the chain from output back to evidence.
Where It Applies
Built for teams shipping in regulated environments
Evidence retrieval systems fit anywhere the quality and traceability of an AI answer determines whether the product is trusted or rejected.
Clinical Decision Support
Real-time, ranked evidence surfaces at the point of care. Clinicians get guideline-aligned answers with sources, not summaries they have to trust blindly.
Precision Medicine Copilots
Ranked retrieval across biomarker, genomic, and protocol literature. Built for platforms where the evidence space is large, fragmented, and high-stakes.
Prior Authorization Support
Evidence-backed rationale for medical necessity decisions, assembled from payer policies, clinical guidelines, and peer-reviewed literature in a single ranked synthesis.
Payer Evidence Summarization
Automated synthesis of clinical review materials across submissions, policies, and literature. Reviewers get structured, source-cited summaries instead of raw document stacks.
Provider Copilots
Staff-facing tools that surface guideline-aligned answers across clinical protocols, formularies, and institutional policies. Built for trust in high-volume, time-constrained workflows.
In Practice
What this looks like in production
A precision medicine platform built on this architecture covers tens of thousands of biomarker, genomic variant, and drug interaction records. Every output links to its peer-reviewed source. During enterprise evaluation, clinical reviewers cited the traceability as the deciding factor in adoption — the difference between a tool that felt experimental and one they were willing to use with patients.
What It Unlocks
Better retrieval quality changes what your product can claim
Lower hallucination risk
Synthesis is constrained to what was retrieved. The model cannot fill gaps with plausible-sounding fabrications when the retrieval layer holds it in bounds.
Clinician and user trust
Explainable answers that show their sources build adoption faster than opaque ones. In regulated environments, trust is an architectural property, not a UX one.
Enterprise defensibility
Outputs that are auditable in procurement reviews, compliance evaluations, and clinical validation studies. The architecture becomes a selling point, not a liability.
Why Vantage
We build this differently
Healthcare-native design
We build for patient data and regulated workflows from the start. HIPAA, audit trails, and evidence accountability are not added later. They are design constraints on the architecture.
Architecture and execution
We design the retrieval system and build it. No handoffs to a separate implementation team. The people who designed the architecture are the people who ship it.
Production, not demos
Every system we design is built to survive enterprise procurement, clinical validation, and security review. We do not build prototypes for pitch decks.
Stronger retrieval means a more defensible product.
If your AI handles patient data, evidence quality, or regulated content, how it retrieves is an architecture decision — not a configuration choice. Walk us through what you are building.